

Key Insights AI Inference Cost Optimization
- AI Inference Costs Dominate Budgets: In 2025, 80-90% of total AI compute spending stems from inference rather than training, driven by massive adoption, real-time demands, and complex model reasoning. This 80-90% rule” underscores the need for proactive management to avoid eroding ROI, as unchecked costs from high-volume requests and data deluges can quickly spiral out of control.
- Strategic Cost Optimization Pillars for ROI: Cloud architects should prioritize model right-sizing, pre-deployment techniques like quantization and pruning, and efficient practices such as batching and caching to slash inference, expenses without sacrificing performance. These methods can yield significant savings; e.g., a 280-fold drop in GPT-3.5 inference costs since 2022; while aligning spend with business value through metrics like “Goodput” for latency-balanced throughput.
- Neoclouds Enable OpEx Flexibility: Hyperscalers like Microsoft are partnering with neocloud providers (e.g., Nebius) to rent GPU capacity, shifting from high-risk CapEx to scalable OpEx models that improve balance sheets and accelerate AI infrastructure rollout. Valued at $17-19 billion through 2031, these deals highlight how enterprises can mitigate budget pressures in Q4 2025 by leveraging third-party data centers for dedicated, cost-predictable AI workloads.
- Hardware as Efficiency Layer: Inference-first accelerators like Google’s TPU Ironwood (v7) and NVIDIA’s Blackwell 2.0 GPUs offer up to 2x performance-per-watt gains, outperforming general-purpose hardware for real-time AI agents and large-scale deployments. CTOs must match workloads to specialized silicon; GPUs for versatile multi-cloud setups or TPUs for TensorFlow-optimized inference; to maximize capital efficiency amid the custom silicon race among AWS, Google, and Microsoft.
A Data-Driven Strategy Guide for CTOs and Cloud aRchitects facing Q4 2025 Budget Pressures
As we close out Q4, 2025, the pressures to demonstrate tangible Return on Investment (ROI) from expansive AI initiatives is intensifying against the backdrop of global IT spending forecasts. Worldwide end-user spending on public cloud services alone is projected to total $723.4 billion in 2025, reflecting a massive 21.5% growth rate driven almost entirely by the accelerated role of AI technologies in business operations.
For Cloud Architects and CTOs, the 2025 mandate is clear: sustain aggressive AI deployment while aggressively curbing the skyrocketing operational expenditures inherent in large-scale Generative AI (Gen AI) adoption. This shift necessitates mastering the AI-Cloud Nexus through strategic infrastructure choices, specialized AI inference optimization, and leveraging the democratization of AI platforms.
The Cloud Nexus: Strategic Infrastructure for Predictable Costs
The foundation of AI success in 2025 is not just adoption, but strategic cloud adoption, integrating distributed, hybrid, and multi-cloud environments under a comprehensive cross-cloud framework. Gartner predicts that 90% of organizations will adopt a hybrid cloud approach through 2027. The most urgent challenge in this environment is achieving data synchronization across the hybrid cloud to support GenAI workloads.
Centralizing Value with CIPS and Cross-Cloud Integration
Organizations are increasingly drawn to the efficiencies provided by Cloud Infrastructure and Platform Services (CIPS) offerings, which deliver integrated IaaS and PaaS capabilities. Complex modern workloads require integrated platforms to simplify development, and operations.
- CIPS Growth: End-user spending on CIPS is expected to grow by 24.2% in 2025 to reach $301 billion.
- Multi-Cloud Driver: The multi-cloud adoption model is driving significant spending on CIPS. A cross cloud integration framework (CCIF) is key to realizing multi-cloud, especially as organizations demand cross-cloud federated GenAI capabilities to service advanced AI use cases.
- Specialized Models: The demand for curated, private, and secure industry and vertical-specific GenAI models (requiring advanced training, inferencing, fine-tuning) is a primary driver of public cloud services growth.
The Rise of Neoclouds and OpEx Optimization
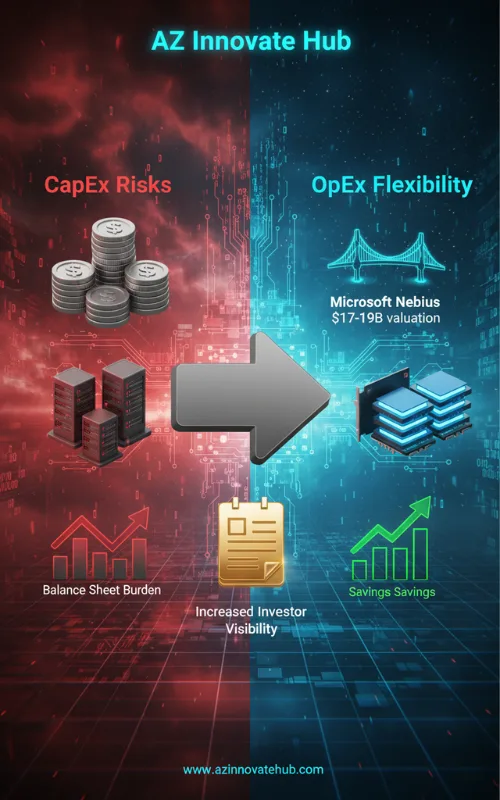
In Q4 2025, major hyperscalers are relying on external infrastructure to meet capacity demands, offering a critical financial lesson for enterprise architects: leverage third-party capacity to shift CapEx risk to OpEx flexibility.
- Neocloud Definition: Neoclouds, such as Nebius, are companies dedicated solely to building and operating date centers using high-performance GPUs for AI and machine learning workloads.
- Strategic Partnerships: The multi-billion dollar agreement between Nebius and Microsoft, valued between $17.4 billion and $19.4 billion through 2031, highlights this trend. Microsoft is securing dedicated GPU capacity starting late in 2025.
- Financial Benefits (OpEx vs. CapEx): Renting infrastructure from neoclouds allows hyperscalers like Microsoft to improve their AI infrastructure faster, with lower upfront costs, and without the financial risk associated with building data centers in-house. Crucially, for budget management, this expenditure can be classified as operational expenditure (OpEx) rather than capital expenditure (CaPex), improving the balance sheet visibility for investors. This model is becoming the new industry standard for large-scale AI infrastructure.
The AI Inference Costs Crisis: Where 80-90% of Budget is Spent
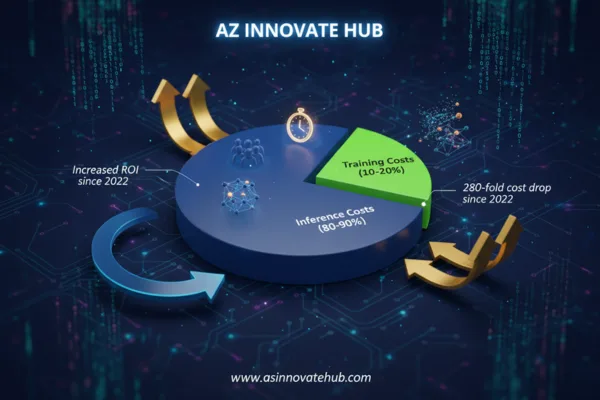
For technical leadership, the central reality of AI deployment is that the ongoing cost of AI inference vastly outweighs the initial training cost. Inference is running the graduate’s job day-to-day, while training is the one-time university expense. Not managing this cost proactively has become a critical roadblock to achieving measurable AI ROI.
Quantifying the Spend: The 80-90% Rule
For most companies deploying AI, the cost of inference, which involves the daily and constant applications of the model, may account for 80-90% of the total compute dollars spent over a model’s active lifecycle. This cumulative cost is driven by frequency and scale: the model serves far more requests during its operational life than during training.
Drivers of Rising Inference Costs in 2025
Despite major leaps in cost optimization that have caused the inference cost for a GPT-3.5-level system to drop over 280-fold between November 2022 and October 2024, total AI inference spending is rising because of four key trends:
- Massive Adoption: Generative AI is moving into core operations across departments like customer service, marketing, and software development, leading to a massive increase in the volume of inference calls.
- The Need for Real-Time Performance (Low Latency): Applications like AI agents and real-time fraud detection demand instant responses. Achieving the required low latency necessitates specialized, premium hardware like the NVIDIA H100 or Google’s inference-focused TPUs.
- Model Complexity and Reasoning: State-of-the-art Large Language Models (LLMs) are larger (hundred of billions of parameters) and perform complex, multistep reasoning (e.g., analyzing complaints, retrieving data, generating a resolution). This advanced reasoning multiplies the compute demand, and therefore the inference cost, for a single user interaction.
- Data Deluge: The continuous flow of ever-increasing data volumes (analyzing large documents, monitoring real-time streams) keeps inference engines constantly busy, adding to the total workload and cost.
Optimization Strategies for Immediate ROI
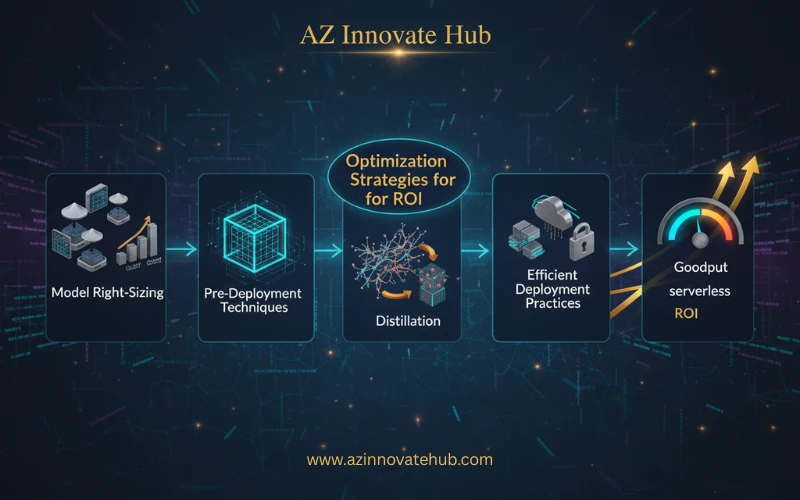
To align inference spend with business value, Cloud Architects must prioritize three optimization pillars:
- Model Right-Sizing: Avoid using massive, multi-billion parameter models for tasks that a smaller, task-specific model could handle efficiently. Compare necessary capabilities against the running price of different open or propriety models.
- Pre-Deployment Techniques (Software Optimization): Significant cost saving can be achieved by making the model run more efficiently on the chosen hardware.
- Quantization: Reducing the numerical precision of weights (e.g., from 32-bit floats to 8-bit or 4-bit integers) makes the model smaller and faster, often with minimal loss in accuracy.
- Pruning: Removing redundant connections within the network makes the model leaner and cheaper to run.
- Distillation: Training a smaller “student” model to mimic the behavior of a larger “teacher” model to gain knowledge transfer and efficiency.
- Efficient Deployment Practices:
- Batching: Grouping multiple requests together to process them simultaneously improves GPU/TPU utilization, significantly increasing throughput and lowering cost per inference.
- Caching: Storing and quickly returning results for identical input prompts avoids redundant model computations.
- Serverless/Dynamic Inference: For variable workloads, serverless platform ensure the company only pays for active compute time, not for idle instances.
Measuring True Efficiency: The Goodput Metric
Traditional metrics like Time to First Token (initial processing time) and Time per Output Token (inter-token latency) are helpful but insufficient for measuring overall cost-performance. IT leaders must adopt the holistic metric “Goodput,” which evaluates the throughput achieved by a system while successfully maintaining target latency levels. This ensures that operational efficiency and user experience remain aligned, maximizing token revenue generation.
Hardware as the Ultimate Optimization Lever in 2025

The hardware choices made in Q4 2025 directly determine the success of inference cost optimization. The market is now defined by a custom silicon race focused on performance-per-watt efficiency, scalability, and inference-first architecture.
The New Inference-First Generation
For large-scale, high-throughput inference, specialized accelerators consistently offer better performance per watt and performance per dollar than general-purpose CPUs or old GPUs.
| Accelerator | Architecture | Date | Key Specifications | Strategic Advantage |
|---|---|---|---|---|
|
NVIDIA RTX 5090 |
Blackwell 2.0 |
Jan, 2025 |
21,760 CUDA Cores, 680 5th Gen Tensor Cores, 32 GB GDDR7 VRAM, 104.8 TFLOPS (FP32) |
Delivers a significant performance leap and strong price-to-performance ratio for demanding AI workloads, suitable for researchers and developers. |
|
Google TPU Ironwood (v7) |
Inference – First |
2025 |
192 GB HBM memory, 7.2 TBps bandwidth, 1.2 Tbps interconnect |
Built specifically for inference at ultra-large scale. Offers up to 2x the performance per watt of its predecessor. |
|
NVIDIA Tesla A100 |
Ampere |
May 2020 |
40GB/80GB HBM2e VRAM, 1,935 GB/s bandwidth, Multi-Instance GPU (MIG) |
Remains a reliable, high-end enterprise choice. Ideal for training massive AI models and offering unmatched memory bandwidth |
|
NVIDIA RTX A6000 |
Ampere |
Apr. 2021 |
48 GB GDDR6 VRAM, ECC support |
A workstation powerhouse valued for stability and reliability in production environments requiring large memory |
|
AWS Inferentia2 |
Custom Silicon |
N/A |
N/A |
Purpose-built for low-latency, high-throughput, and budget-friendly inference on AWS |
Procurement and Cost-Efficiency Decisions
CTOs must match the workload to the optimal hardware platform to maximize capital efficiency:
- GPU Versatility vs. TPU Specialization: GPUs, backed by the mature CUDA ecosystem, offer flexibility for multi-cloud deployments and custom kernel experimentation (e.g., NVIDIA H100/A100). TPUs, conversely, are the “scalpel”; optimized for TensorFlow/JAX workloads and offering superior efficiency for high-throughput, large-scale inference within Google Cloud.
- The Ironwood Advantage: The launch of the inference-first Ironwood TPU (v7) in 2025, leveraging advanced liquid cooling and achieving up to 2x the performance per watt of its predecessor, makes Google Cloud the optimal choice for companies deploying complex, real-time AI agents and ranking systems.
- Custom Silicon Race: Recognize that every major cloud provider is prioritizing custom chips (Google TPUs, AWS Inferentia/Trainium, Microsoft Maia) to gain control over cost, power efficiency, and performance through tight hardware-software co-design.
For organizations seeking dedicated capacity outside the hyperscalers, GPU hosting services offer measurable monthly rates. For example, a dedicated server with a high-end NVIDIA A40 (48 GB GDDR6) is available for approximately $439.00/mo, while a dual-RTX 5090 (Blackwell 2.0) server is listed at $859.00/mo. Choosing the optimal GPU based on workload and budget is critical for the AI inference journey in 2025.
Democratized Innovation and Scaling Value
The AI revolution is defined by the democratization of productivity, moving sophisticated tools out of the research lab and into daily enterprise workflows, enabling measurable ROI for enterprise and small-to-medium businesses alike.
The New AI-as-a-Service (AIaaS) Paradigm
The AI SaaS market commands extraordinary valuations; up to 25.8x revenue multiples, drastically exceeding the 2.5-7.0x range of traditional SaaS. This valuation premium reflects the demonstrable ROI delivered by AI in automating high-value tasks.
- The Freemium Blueprint (OpenAI): OpenAI’s strategic expansion of free access to core features like ChatGPT Projects (as of September 3, 2025) has redefined AIaaS economics.
- Adoption and Conversion: This approach has helped OpenAI build a base of 700 million weekly active users by August 2025. Critically, the conversion rate from free-to-paid Plus subscriptions is 5.8% outpacing the industry average of 2-5%.
- Retention: The model demonstrates exceptional sticky value, with 89% of Plus users retaining subscriptions after one quarter and 75% remaining after three quarters.
- Enterprise Penetration: By 2025, 5 million business users, including 80% of Fortune 500 companies, have adopted ChatGPT for AI-driven automation and data orchestration.
- Competitive Pricing Shifts: OpenAI’s success has forced competitors to pivot toward flexible, value-based pricing.
- Usage-Based Models: DeepSeek, for instance, countered with a pay-as-you-go model (as low as $0.0005 per 1K tokens) targeting cost-sensitive SMEs.
- Integrated Platforms: Microsoft Copilot, priced at $30/user/month for existing 365 subscribers, deepens AI integration into everyday productivity tools (Excel, Outlook, Teams).
The Agentic Enterprise: Scaling productivity in 2025
A major trend for 2025 is the evolution from simple chatbots to sophisticated multi-agent systems. These AI agents are predicted to be the main use case for professional or enterprise-level AI.
- Complex Reasoning: AI agents handle complex tasks by interacting, delegating, and reasoning collaboratively. Running these sophisticated systems requires scaling accelerated computing resources and necessitates hardware specialized for multi-modal context switching, dynamic memory management, and cross-agent communication. Google Cloud offers Google Agentspace to help users build, manage, and adopt these systems at scale.
- Customer Experience (CX) Impact: Research from 2025 shows that 84% of user experience improved digital journeys with AI-powered chatbots, with a 46% boost in customer satisfaction reported in sectors like finance. AIaaS can automate up to 30% of repletive text processing and document handling.
- SMB Adoption: Advancements in cloud and SaaS models have made AI tools affordable and scalable for smaller businesses. A Deloitte study predicts a 50% increase in small business AI adoption in 2025, driven by “plug-and-play solutions” like ChatGPT and Microsoft Copilot.
Conclusion: Q4 2025 Actionable Priorities for ROI

For CTOs and Cloud Architects navigating Q4 2025 budget cycles, focusing capital efficiency on the AI-Cloud Nexus means prioritizing inference costs over training costs, leveraging specialized infrastructure, and maximizing the sticky value of AI services.
| Strategic Priority | Justification (ROI Metric) | Prescriptive Action |
|---|---|---|
|
Control Inference TCO |
Inference accounts for 80-90% of a model’s lifetime cost. Unmanaged costs are the chief roadblock to ROI. |
Mandate model right-sizing and apply pre-deployment optimization techniques (Quantization, Pruning, Distillation). |
|
Optimize Compute Efficiency |
Specialized hardware (TPUs, Inferentia, Blackwell 2.0) drives higher performance per watt |
Select inference-first hardware like TPU Ironwood for real-time agents/ranking in GCP or evaluate multi-GPU dedicated servers for flexible workloads (e.g., dual-RTX 5090) |
|
Embrace OpEx for Capacity |
Leveraging neoclouds (Nebius, CoreWeave) converts substantial infrastructure spending from CapEx to flexible OpEx |
Analyze long-term capacity needs and explore dedicated GPU infrastructure contracts with Neocloud providers to mitigate financial risk and accelerate deployment |
|
Leverage AIaaS Value |
AI SaaS platforms command 25.8x revenue multiples due to high retention (89% retention after Q1) and proven productivity gains. |
Invest in platforms with proven freemium strategies and strong enterprise integration (ChatGPT, Microsoft Copilot), especially those supporting the shift towards AI agents. |
By aggressively managing costs through hardware specialization, software optimization, and strategic capacity acquisition, enterprises can ensure that the massive investment flowing into the AI-Cloud Nexus in 2025 generates profitable, scalable, and sustainable business value.



Pingback: What is AI Inference? Strategic Compass for Tech Innovators - AZ Innovate Hub
Pingback: %Why AI Companies Offer Free Premium Plans in India | Real Strategy Explained% - AZ Innovate Hub