
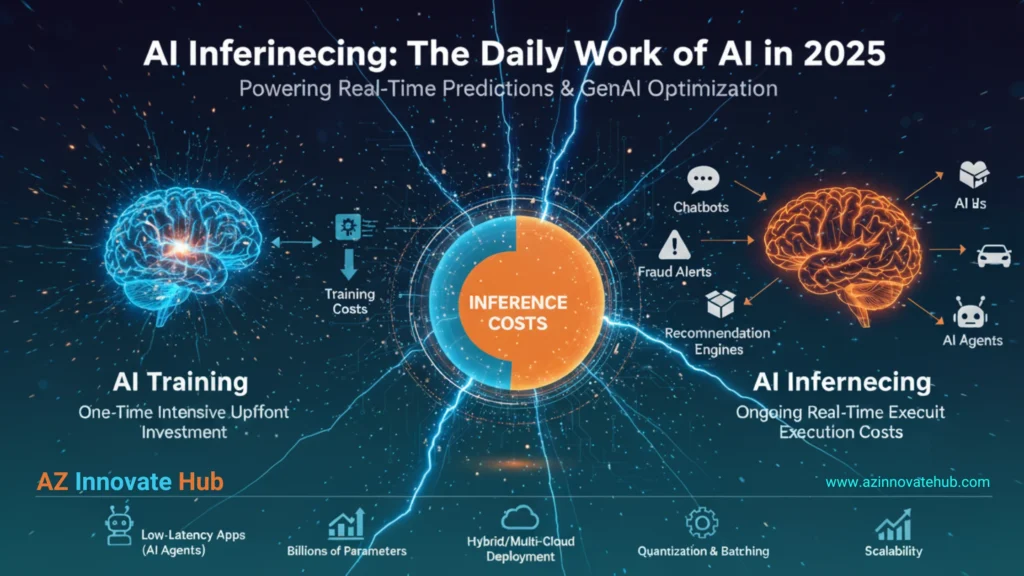
Key Insights: What is "AI Inference?"
- AI Inference Drives Costs: AI inference, the real-time application of trained AI models, consumes 80-90% of compute costs due to its continuous, high-volume use in applications like chatbots and fraud detection, making GenAI cost management critical for ROI in 2025.
- Trends Fuel Inference Demand: Massive GenAI adoption, low-latency needs for real-time AI agents, complex models with billions of parameters, and growing data streams escalate inference costs, requiring robust cloud infrastructure 2025 and specialized hardware like GPUs and TPUs.
- Optimization is Essential: Techniques like model right-sizing, quantization, and dynamic batching reduce inference costs while maintaining speed and accuracy, enabling efficient multi-cloud AI deployment and cost-effective operations for cloud architects.
- Hybrid Cloud Enhances Scalability: Hybrid and multi-cloud AI deployment models offer flexibility, combining public cloud scalability with on-premise control, while edge inference reduces latency and enhances privacy for real-time systems.
For Chief Technology Officers (CTOs) and Cloud Architects navigating the explosive growth of artificial intelligence, understanding the operational heart of AI known as AI inference is no longer optional; it is fundamental to strategic planning and financial sustainability. As organizations move beyond pilot projects into enterprise-wide AI adoption, the true nature of AI’s computational demands is coming into sharp focus.
Defining AI Inference: The Daily Work of Intelligent Systems
AI inference is the process of running a trained AI model to make real-time predictions, generate content, or draw actionable conclusions from new, unseen data.
In essence, inference is the “doing” part of artificial intelligence. It represents the AI model’s “moment of truth,” where it applies the knowledge gained during training to solve a task or provide an output. This crucial process powers nearly every real-world application of AI:
- Chatbots and virtual assistants: Generating linguistic responses based on user queries.
- Fraud detection: Instantly analyzing financial transaction to flag suspicious activity.
- Recommendation engines: Predicting user preferences to suggest products or media.
- Autonomous systems: Interpreting sensor data to navigate dynamic environments, such as self-driving cars recognizing a stop sign on an unfamiliar road.
AI inference mirrors human cognition, where we draw on prior knowledge (training) to interpret a new situation (inference). The model generalizes from its stored representation by a complex set of rules encoded in model weights to interpret new, real-time input. The goal is always to calculate an actionable result, whether that is a probability score from spam or a complex decision for an industrial robot.
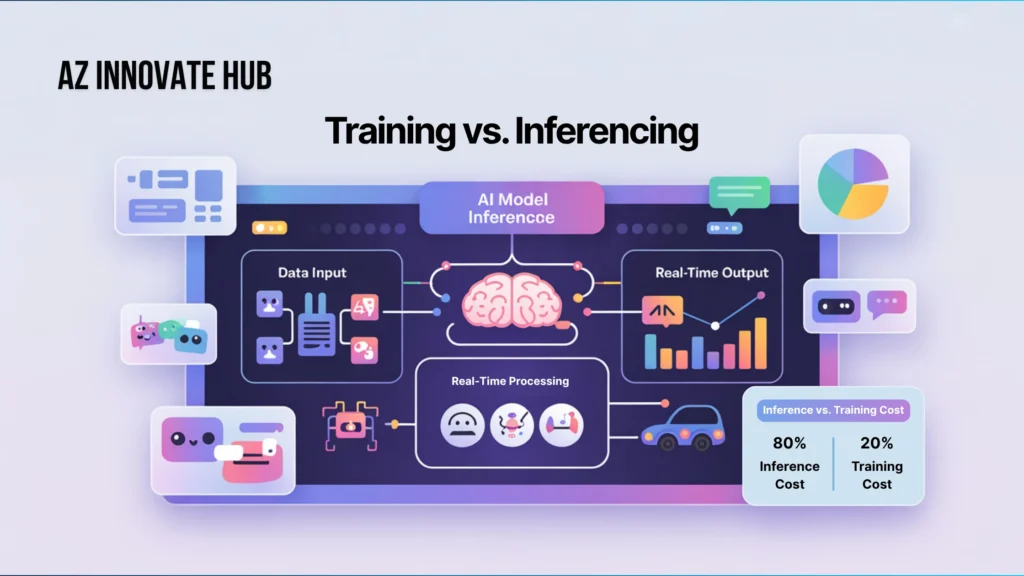
Inference vs. Training: Understanding the Cost Divide
The AI model lifecycle involves two primary stages: training and inferencing.
| Feature | AI Training | AI Inferencing (Execution) |
|---|---|---|
|
Objective |
Build a new model or teach it a new skill. |
Use the trained model to execute real-time predictions. |
|
Process |
Computationally intensive, iterative learning from massive datasets. |
A single, fast “forward pass” of new data, applying stored knowledge. |
|
Duration |
A one-time or infrequent, upfront investment. |
Ongoing, constant application across the model’s lifetime. |
|
Business Focus |
Model accuracy and capability. |
Speed (latency), scale, and cost-efficiency. |
While training an AI model, especially large language models (LLMs), can cost millions of dollars and weeks of processing time, this cost is often dwarfed by the expense of AI inferencing. Training is a one-time investment in compute, but inference is ongoing, happening millions or even billions of times over a model’s operational lifespan.
Due to this continuous, high-volume demand, inference is the model’s “daily work”. On average, approximately 80-90% of an AI model’s life is spent in inferencing mode. Consequently, most of the total AI compute cost, operational energy consumption, and carbon footprint stems from serving these models to users, not training them.
Why AI Inferencing is Critical: The Generative AI Tsunami
The high costs and massive scale of AI inferencing have been rapidly escalating, making optimization defining challenge for CTOs and Cloud Architects in 2025. This criticality is driven by four major trends converging across the enterprise landscape:
1. Massive Adoption: The Pervasive Spread of Generative AI
The latest breakthroughs in Generative AI (GenAI) have triggered an explosion in AI usage across all business functions. GenAI is rapidly integrating into core enterprise workflows:
- Customer Service: AI agents handle common inquiries at scale.
- Marketing and Sales: Personalized ad copy and hyper-personalization engines drive engagement.
- Software Development: Code generation models accelerate development timelines.
This surge in use translates directly into unprecedented GenAI cost management challenges. When a service like ChatGPT processes over a billion queries daily, the dramatic increase in inference volume, coupled with the computational demands of the models, creates “excessive pressure on data center resources”.
2. Low-Latency Needs: The Demand for Real-Time Intelligence
Many mission-critical AI applications require responses in milliseconds. This “Need for Speed” is necessary for handling real-time data input and delivering near-instantaneous, actionable results.
For example, real-time (online) inference is essential for:
- Live Language translation.
- Instantaneous fraud alerts.
- Autonomous driving decisions.
The rise of complex, multistep
AI agent, which are system designed to automate routine tasks and interact with users autonomously, further necessitates exceptionally low latency. If an AI agent cannot execute its inference tasks rapidly, the user experience suffers, and its utility is compromised.
3. Model Complexity: Scaling to Billions of Parameters
GenAI models, particularly Large Language Models (LLMs), are orders of magnitude bigger than previous AI models. These models scale to hundreds of billions or even trillions of parameters.
Model complexity requires significantly greater computational resources for each individual inference. Running large deep learning models involves extensive matrix multiplication, which is highly compute-intensive. For instance, running a 70-billion parameter model requires at least 150 gigabytes of memory, exceeding the capacity of many high-end GPUs, forcing operators to split operations across multiple processors.
4. Data Volumes: The Real-Time Data Stream
The continuous flow of live, real-world-data from IoT sensors, financial transaction streams, and user interactions, requires constant analysis. Streaming inference, often used in IoT systems, involves a constant pipeline of data flowing into the ML algorithm to continually make predictions, such as sensing patterns that indicate machine trouble ahead. This requires robust, low-latency network connections and vast data centers to maintain and cool the necessary infrastructure.
The Imperative of GenAI Cost Management
The confluence of massive adoption and highly complex models means that GenAI cost management is paramount. Inference costs, spanning energy consumption, hardware wear-and-tear, and operational expenses, can quickly erode the Return on Investment (ROI) of AI initiatives without rigorous optimization.
The Specialized Hardware Tax
Achieving the required speed and scale necessitates powerful, energy-hungry hardware. AI inference relies heavily on specialized computing components:
- Graphics Processing Units (GPUs): Key hardware components designed to perform mathematical calculations quickly, making compute-hungry inference possible.
- Specialized Accelerators: Engineers are constantly developing specialized chips, such as Tensor Processing Units (TPUs) and Application-Specific Integrated Circuits (ASICs), optimized for the matrix multiplication operations that dominate deep learning. These accelerators can speed up inferencing tasks more efficiently than traditional CPUs.
The deployment of these highly specialized hardware units escalates CapEx and OpEx, requiring advanced orchestration and management to ensure they operate at peak efficiency and justify their expense.
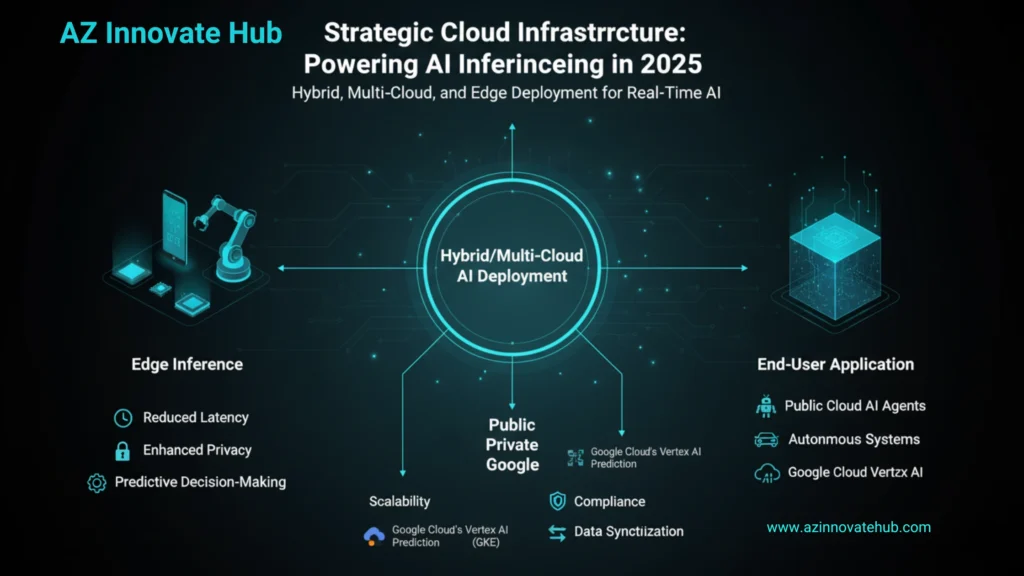
Strategic Cloud Infrastructure: Hybrid and Multi-Cloud Deployment
To manage the enormous scale, computational requirements, and cost variability associated with modern AI inferencing, organizations must adopt sophisticated deployment strategies focused on flexibility, scalability, and proximity to data.
The Rise of Hybrid and Multi-Cloud AI Deployment
The default deployment model for large AI operations is trending toward hybrid and multi-cloud AI deployment. This approach allows enterprises to leverage the specific strengths of various environments.
- Public Cloud Inference (Cloud Inference): The most common approach, offering immense scalability and computational resources, running on powerful remote servers in a data center. Cloud providers offer managed services, like Google Cloud’s Vertex AI Prediction and Google Kubernetes Engine (GKE), to deploy models as scalable endpoints and handle complex server orchestration.
- Hybrid Cloud Infrastructure: Provides the option of keeping sensitive AI workloads on-premises (on private servers) while running other workloads in public cloud environments. This offers enhanced data synchronization, compliance, and control over proprietary data sets.
- Edge Inference: Performing inference directly on the device where data is generated (e.g., smartphone, sensor, or industrial robot). This is the “last mile” of AI inference, bringing capabilities close to the data source.
Edge inference offers critical advantages for CTOs managing real-time systems: reduced latency (nearly instantaneous responses without a network hop), enhanced privacy (sensitive data is processed locally), and offline functionality, ensuring continuous operation even in disconnected environments. This decentralization enables better object detection, behavior recognition, and predictive decision-making in field operations.
AI Inference Optimization: Strategies for Performance and Cost Reduction
Given that the bulk of AI cost is tied to inferencing, optimization is essential for achieving commercial viability. Cloud architects must strategically implement techniques to cut costs while maintaining the required low latency and output accuracy.
1 Optimization Techniques for Model Efficiency
AI inference optimization efforts are focused on improving performance across the entire compute stack of hardware, software, and middleware.
Model Right-Sizing and Selection
The initial challenge is choosing or building the right model for the tasks. More complex algorithms can handle wider inputs and make subtler inferences, but they demand exponentially greater computing resources. Strategic model selection ensures the model fits the needs in terms of complexity versus compute hunger.
Quantization
Quantization is a critical software approach for accelerating inferencing. It involves reducing the precision of the model’s weights. By converting weights from high-precision 32-bit floating point numbers to lower-precision representations, such as 8-bit integers, computations are sped up, and memory requirements are significantly reduced. This technique reduces the model’s memory load without significantly losing accuracy.
Pruning (Model Compression)
Pruning removes unnecessary weights and connections from the model, effectively reducing its overall size without causing a significant impact on accuracy. This lightweighting makes the model more efficient for inference deployment.
2. Optimization Techniques for Deployment and Throughput
Deployment-level optimization focuses on efficiently feeding data to the hardware to maximize utilization and throughput:
Batching (Batch Inference)
Batch inference involves generating predictions offline by processing large volumes of data (batches) at scheduled intervals. This is highly cost-effective for non-urgent tasks like large-scale document categorization or overnight financial analysis.
Dynamic Batching
For real-time systems, dynamic batching is essential. This technique allows the runtime environment to consolidate multiple user requests into a single, large batch. By increasing the size of the batch, the specialized GPU hardware can operate at or near full capacity, thereby increasing overall throughput and efficiency.
Middleware Optimization (Graph Fusion and Parallel Tensors)
Middleware bridges the gap between software and hardware. Frameworks like PyTorch can implement advanced techniques to accelerate inferencing:
- Graph Fusion: Reduces the number of nodes in the communication graph, minimizing time-consuming round trips between the CPU and the specialized accelerator hardware (like GPUs or TPUs).
- Parallel Tensors: For extremely large models (like the 70-billion parameter models), the computational graph must be strategically split into chunks that can be spread across and run simultaneously on multiple GPUs. This technique addresses the memory bottleneck inherent in serving LLMs.
Combining these optimization levers, such as graph fusion, kernel optimization, and parallel tensors has demonstrated significant improvements in latency, crucial for maintaining fast response times (e.g., achieving 29 milliseconds per token latency in a 70-billion parameter model test).
Conclusion
AI inferencing has transitioned from a specialized computing topic to the single largest operational cost factor in modern enterprise technology. For CTOs and Cloud Architects in 2025, strategic planning must be centered on achieving efficiency at scale. The widespread integration of GenAI demands immediate and continuous focus on GenAI cost management through optimized cloud infrastructure deployment, particularly in hybrid and multi-cloud AI deployment models and aggressive application of AI inference optimization techniques like quantization and dynamic batching.
The ability to deploy complex, low-latency AI agents while controlling ballooning compute cost will determine which enterprises lead the market in the coming years.
To deepen your understanding of the financial and architectural planning required for this crucial shift, download our advanced guide outlining Q4 2025 strategies for managing massive inference costs: Access our comprehensive guide here.



